Computer vision is one of the most discussed fields in the AI industry, thanks to its potential applications across a wide range of real-time tasks. In recent years, computer vision frameworks have advanced rapidly, with modern models now capable of analyzing facial features, objects, and much more in real-time scenarios. Despite these capabilities, human motion transfer remains a formidable challenge for computer vision models. This task involves retargeting facial and body motions from a source image or video to a target image or video. Human motion transfer is widely used in computer vision models for styling images or videos, editing multimedia content, digital human synthesis, and even generating data for perception-based frameworks.
In this article, we focus on MagicDance, a diffusion-based model designed to revolutionize human motion transfer. The MagicDance framework specifically aims to transfer 2D human facial expressions and motions onto challenging human dance videos. Its goal is to generate novel pose sequence-driven dance videos for specific target identities while maintaining the original identity. The MagicDance framework employs a two-stage training strategy, focusing on human motion disentanglement and appearance factors like skin tone, facial expressions, and clothing. We will delve into the MagicDance framework, exploring its architecture, functionality, and performance compared to other state-of-the-art human motion transfer frameworks. Let's dive in.
As mentioned earlier, human motion transfer is one of the most complex computer vision tasks because of the sheer complexity involved in transferring human motions and expressions from the source image or video to the target image or video. Traditionally, computer vision frameworks have achieved human motion transfer by training a task-specific generative model including GAN or Generative Adversarial Networks on target datasets for facial expressions and body poses. Although training and using generative models deliver satisfactory results in some cases, they usually suffer from two major limitations.
- They rely heavily on an image warping component as a result of which they often struggle to interpolate body parts invisible in the source image either due to a change in perspective or self-occlusion.
- They cannot generalize to other images sourced externally that limits their applications especially in real-time scenarios in the wild.

Modern diffusion models have demonstrated exceptional image generation capabilities across different conditions, and diffusion models are now capable of presenting powerful visuals on an array of downstream tasks such as video generation & image inpainting by learning from web-scale image datasets. Owing to their capabilities, diffusion models might be an ideal pick for human motion transfer tasks. Although diffusion models can be implemented for human motion transfer, it does have some limitations either in terms of the quality of the generated content, or in terms of identity preservation or suffering from temporal inconsistencies as a result of model design & training strategy limits. Furthermore, diffusion-based models demonstrate no significant advantage over GAN frameworks in terms of generalizability.
To overcome the hurdles faced by diffusion and GAN based frameworks on human motion transfer tasks, developers have introduced MagicDance, a novel framework that aims to exploit the potential of diffusion frameworks for human motion transfer demonstrating an unprecedented level of identity preservation, superior visual quality, and domain generalizability. At its core, the fundamental concept of the MagicDance framework is to split the problem into two stages : appearance control and motion control, two capabilities required by image diffusion frameworks to deliver accurate motion transfer outputs.

The above figure gives a brief overview of the MagicDance framework, and as it can be seen, the framework employs the Stable Diffusion model, and also deploys two additional components : Appearance Control Model and Pose ControlNet where the former provides appearance guidance to the SD model from a reference image via attention whereas the latter provides expression/pose guidance to the diffusion model from a conditioned image or video. The framework also employs a multi-stage training strategy to learn these sub-modules effectively to disentangle pose control and appearance.
In summary, the MagicDance framework is a
- Novel and effective framework consisting of appearance-disentangled pose control, and appearance control pretraining.
- The MagicDance framework is capable of generating realistic human facial expressions and human motion under the control of pose condition inputs and reference images or videos.
- The MagicDance framework aims to generate appearance-consistent human content by introducing a Multi-Source Attention Module that offers accurate guidance for Stable Diffusion UNet framework.
- The MagicDance framework can also be utilized as a convenient extension or plug-in for the Stable Diffusion framework, and also ensures compatibility with existing model weights as it does not require additional fine-tuning of the parameters.
Additionally, the MagicDance framework shows exceptional generalization capabilities for both appearance and motion generalization.
- Appearance Generalization : The MagicDance framework demonstrates superior capabilities when it comes to generating diverse appearances.
- Motion Generalization : The MagicDance framework also has the ability to generate a wide range of motions.
MagicDance : Objectives and Architecture
For a given reference image either of a real human or a stylized image, the primary objective of the MagicDance framework is to generate an output image or an output video conditioned on the input and the pose inputs P, F where P represents human pose skeleton and F represents the facial landmarks. The generated output image or video should be able to preserve the appearance and identity of the humans involved along with the background contents present in the reference image while retaining the pose and expressions defined by the pose inputs.
Architecture
During training, the MagicDance framework is trained as a frame reconstruction task to reconstruct the ground truth with the reference image and pose input sourced from the same reference video. During testing to achieve motion transfer, the pose input and the reference image is sourced from different sources.
The overall architecture of the MagicDance framework can be split into four categories: Preliminary stage, Appearance Control pretraining, Appearance-disentangled Pose Control, and Motion Module.
Preliminary Stage
Latent Diffusion Models or LDM represent uniquely designed diffusion models to operate within the latent space facilitated by the use of an autoencoder, and the Stable Diffusion framework is a notable instance of LDMs that employs a Vector Quantized-Variational AutoEncoder and temporal U-Net architecture. The Stable Diffusion model employs a CLIP-based transformer as a text encoder to process textual inputs by converting text inputs into embeddings. The training phase of the Stable Diffusion framework exposes the model to a text condition and an input image with the process involving the encoding of the image to a latent representation, and subjects it to a predefined sequence of diffusion steps directed by a Gaussian method. The resultant sequence yields a noisy latent representation that provides a standard normal distribution with the primary learning objective of the Stable Diffusion framework being denoising the noisy latent representations iteratively into latent representations.
Appearance Control Pretraining
A major issue with the original ControlNet framework is its inability to control appearance amongst spatially varying motions consistently although it tends to generate images with poses closely resembling those in the input image with the overall appearance being influenced predominantly by textual inputs. Although this method works, it is not suited for motion transfer involving tasks where its not the textual inputs but the reference image that serves as the primary source for appearance information.
The Appearance Control Pre-training module in the MagicDance framework is designed as an auxiliary branch to provide guidance for appearance control in a layer-by-layer approach. Rather than relying on text inputs, the overall module focuses on leveraging the appearance attributes from the reference image with the aim to enhance the framework’s ability to generate the appearance characteristics accurately particularly in scenarios involving complex motion dynamics. Furthermore, it is only the Appearance Control Model that is trainable during appearance control pre-training.
Appearance-disentangled Pose Control
A naive solution to control the pose in the output image is to integrate the pre-trained ControlNet model with the pre-trained Appearance Control Model directly without fine-tuning. However, the integration might result in the framework struggling with appearance-independent pose control that can lead to a discrepancy between the input poses and the generated poses. To tackle this discrepancy, the MagicDance framework fine-tunes the Pose ControlNet model jointly with the pre-trained Appearance Control Model.
Motion Module
When working together, the Appearance-disentangled Pose ControlNet and the Appearance Control Model can achieve accurate and effective image to motion transfer, although it might result in temporal inconsistency. To ensure temporal consistency, the framework integrates an additional motion module into the primary Stable Diffusion UNet architecture.
MagicDance : Pre-Training and Datasets
For pre-training, the MagicDance framework makes use of a TikTok dataset that consists of over 350 dance videos of varying lengths between 10 to 15 seconds capturing a single person dancing with a majority of these videos containing the face, and the upper-body of the human. The MagicDance framework extracts each individual video at 30 FPS, and runs OpenPose on each frame individually to infer the pose skeleton, hand poses, and facial landmarks.
For pre-training, the appearance control model is pre-trained with a batch size of 64 on 8 NVIDIA A100 GPUs for 10 thousand steps with an image size of 512 x 512 followed by jointly fine-tuning the pose control and appearance control models with a batch size of 16 for 20 thousand steps. During training, the MagicDance framework randomly samples two frames as the target and reference respectively with the images being cropped at the same position along the same height. During evaluation, the model crops the image centrally instead of cropping them randomly.
MagicDance : Results
The experimental results conducted on the MagicDance framework are demonstrated in the following image, and as it can be seen, the MagicDance framework outperforms existing frameworks like Disco and DreamPose for human motion transfer across all metrics. Frameworks consisting a “*” in front of their name uses the target image directly as the input, and includes more information compared to the other frameworks.
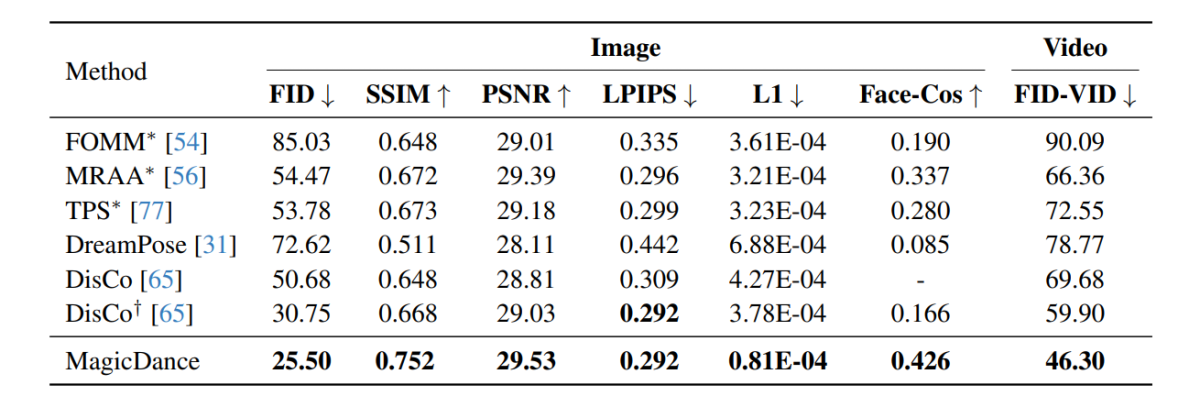
It is interesting to note that the MagicDance framework attains a Face-Cos score of 0.426, an improvement of 156.62% over the Disco framework, and nearly 400% increase when compared against the DreamPose framework. The results indicate the robust capacity of the MagicDance framework to preserve identity information, and the visible boost in performance indicates the superiority of the MagicDance framework over existing state-of-the-art methods.
The following figures compare the quality of human video generation between the MagicDance, Disco, and TPS frameworks. As it can be observed, the results generated by the GT, Disco, and TPS frameworks suffer from inconsistent human pose identity and facial expressions.

Furthermore, the following image demonstrates the visualization of facial expression and human pose transfer on the TikTok dataset with the MagicDance framework being able to generate realistic and vivid expressions and motions under diverse facial landmarks and pose skeleton inputs while accurately preserving identity information from the reference input image.

It is worth noting that the MagicDance framework boasts of exceptional generalization capabilities to out-of-domain reference images of unseen pose and styles with impressive appearance controllability even without any additional fine-tuning on the target domain with the results being demonstrated in the following image.

The following images demonstrate the visualization capabilities of MagicDance framework in terms of facial expression transfer and zero-shot human motion. As it can be seen, the MagicDance framework generalizes to in-the-wild human motions perfectly.

MagicDance : Limitations
OpenPose is an essential component of the MagicDance framework as it plays a crucial role for pose control, affecting the quality and temporal consistency of the generated images significantly. However, the MagicDance framework still finds it a bit challenging to detect facial landmarks and pose skeletons accurately, especially when the objects in the images are partially visible, or show rapid movement. These issues can result in artifacts in the generated image.
Conclusion
In this article, we have talked about MagicDance, a diffusion-based model that aims to revolutionize human motion transfer. The MagicDance framework tries to transfer 2D human facial expressions and motions on challenging human dance videos with the specific aim of generating novel pose sequence driven human dance videos for specific target identities while keeping the identity constant. The MagicDance framework is a two-stage training strategy for human motion disentanglement and appearance like skin tone, facial expressions, and clothes.
MagicDance is a novel approach to facilitate realistic human video generation by incorporating facial and motion expression transfer, and enabling consistent in the wild animation generation without needing any further fine-tuning that demonstrates significant advancement over existing methods. Furthermore, the MagicDance framework demonstrates exceptional generalization capabilities over complex motion sequences and diverse human identities, establishing the MagicDance framework as the lead runner in the field of AI assisted motion transfer and video generation.
#Ai, #Amp, #Animation, #Applications, #Approach, #Architecture, #Art, #Article, #ArtificialIntelligence, #Attention, #Background, #Challenge, #Change, #Clothing, #Complexity, #Computer, #ComputerVision, #Dance, #Data, #Datasets, #Design, #Developers, #Diffusion, #DiffusionModels, #Dynamics, #Editing, #Embeddings, #Experimental, #Extension, #Features, #Framework, #Fundamental, #GAN, #Generative, #GenerativeModels, #Hand, #Human, #Humans, #Identities, #Identity, #ImageGeneration, #Images, #Industry, #Integration, #Issues, #It, #Learn, #Learning, #MagicDance, #Method, #Model, #Module, #MotionControl, #MotionTransfer, #Movement, #Networks, #Nvidia, #Objects, #One, #Other, #Perception, #Performance, #PlugIn, #Process, #Scale, #Skeletons, #Skin, #Space, #StableDiffusion, #Strategy, #Styles, #Sub, #Synthesis, #Testing, #Text, #Tiktok, #Time, #Training, #Transfer, #Tuning, #Video, #VideoGeneration, #Videos, #Vision, #Web, #X, #ZeroShot
Published on The Digital Insider at https://thedigitalinsider.com/magicdance-realistic-human-dance-video-generation/.
Comments
Post a Comment
Comments are moderated.