In today’s tech-driven world, text-to-speech (TTS) technology is becoming a vital resource for businesses seeking to enhance accessibility, automate processes, and engage users more effectively. As audio content continues to grow in popularity across platforms like e-learning, customer service, and media, the demand for advanced, natural-sounding TTS solutions is on the rise.
This curated list presents the top text-to-speech APIs available, providing business executives with cutting-edge tools to integrate high-quality speech synthesis into their products and services. These APIs offer seamless, scalable solutions for improving customer experience, boosting productivity, and staying ahead in the content creation space.
Deepgram's Aura Text-to-Speech API offers lightning-fast, human-like voice synthesis optimized for real-time applications such as conversational AI, customer support, and voicebots. With less than 250 ms latency, it ensures seamless, natural interactions, making it ideal for businesses that prioritize responsiveness and high-quality voice output.
Aura a natural-sounding, high-throughput text-to-speech model delivers enterprise-grade scalability, allowing for efficient processing of large volumes of text-to-speech conversions with minimal delay. Its wide selection of male and female voices is fine-tuned for conversational use cases, making it perfect for industries like healthcare, customer service, and media.
Trusted by top enterprises, Deepgram's API excels in balancing voice quality, speed, and cost, positioning it as a leading solution for businesses seeking to integrate advanced TTS capabilities.
Key features of Deepgram:
- Deepgram's Aura Text-to-Speech API provides real-time, human-like voice synthesis with less than 250 ms latency.
- Optimized for conversational AI and customer support, it ensures seamless and natural interactions.
- Aura supports enterprise-grade scalability, handling large volumes of text-to-speech conversions efficiently.
- Offers a diverse range of fine-tuned male and female voices for various industries, including healthcare and media.
- Trusted by top enterprises, Aura delivers a perfect balance of voice quality, speed, and cost.

Google Cloud Text-to-Speech is a powerful and versatile TTS service that leverages Google's advanced machine learning and neural network technologies to generate high-quality, natural-sounding speech from text. The service offers a wide array of voices across multiple languages and variants, including WaveNet voices that produce highly natural and human-like speech. With its robust API, Google Cloud Text-to-Speech can be easily integrated into various applications, enabling developers to create voice-enabled experiences across different platforms and devices.
The service supports a range of audio formats and allows for extensive customization of speech output, including pitch, speaking rate, and volume. Google Cloud Text-to-Speech also offers features like text and SSML support, making it suitable for a variety of use cases, from creating voice interfaces for IoT devices to generating audio content for podcasts and video narration. With its scalable infrastructure and integration with other Google Cloud services, it provides a comprehensive solution for businesses looking to incorporate high-quality speech synthesis into their products and services.
Key features of Google Cloud Text-to-Speech:
- WaveNet voices for highly natural and expressive speech output
- Support for multiple languages and voice variants
- Customizable speech parameters (pitch, rate, volume)
- Integration with other Google Cloud services for enhanced functionality
- Scalable infrastructure to handle varying workloads
ElevenLabs offers a state-of-the-art text-to-speech API that leverages advanced neural network models to produce highly natural and expressive speech. The platform is designed to cater to a wide range of applications, from content creation to accessibility tools, providing developers with the ability to generate lifelike voices in multiple languages and accents. ElevenLabs' API is known for its high-quality output and customization options, allowing users to fine-tune voice characteristics to suit their specific needs.
With its focus on realistic speech synthesis, ElevenLabs has gained popularity among content creators, game developers, and businesses looking to enhance their audio experiences. The platform offers both pre-made voices and the ability to clone voices, giving users flexibility in creating unique audio content. ElevenLabs' commitment to continuous improvement and expanding language support makes it a strong contender in the text-to-speech market.
Key features of ElevenLabs:
- Advanced neural network models for highly natural speech synthesis
- Support for multiple languages and accents
- Voice cloning capabilities for creating custom voices
- Customizable voice parameters for fine-tuning output
- Low latency and high-throughput API for real-time applications

Amazon Polly is a cloud-based TTS service that uses advanced deep learning technologies to synthesize natural-sounding human speech. As part of the Amazon Web Services (AWS) ecosystem, Polly offers a wide range of voices in multiple languages and accents, allowing developers to create applications that can speak with lifelike pronunciation and intonation. The service is designed to be easily integrated into existing applications, websites, or products, enabling businesses to enhance user experiences and accessibility.
Polly's neural text-to-speech voices provide even more natural and expressive speech output, making it suitable for a variety of use cases, including e-learning platforms, accessibility tools, and voice-enabled devices. The service also supports Speech Synthesis Markup Language (SSML), allowing fine-grained control over speech output, including emphasis, pitch, and speaking rate. With its pay-as-you-go pricing model, Amazon Polly offers a cost-effective solution for businesses of all sizes to incorporate high-quality speech synthesis into their products and services.
Key features of Amazon Polly:
- Wide selection of lifelike voices in multiple languages and accents
- Neural text-to-speech technology for enhanced naturalness
- Support for Speech Synthesis Markup Language (SSML)
- Easy integration with AWS ecosystem and other applications
- Pay-as-you-go pricing model for cost-effective scaling
Microsoft Azure's Text-to-Speech service is part of the Azure Cognitive Services suite, offering a comprehensive and scalable solution for converting text into lifelike speech. Leveraging Microsoft's extensive research in neural text-to-speech technology, the service provides a wide array of natural-sounding voices across numerous languages and variants. Azure's TTS is designed to integrate seamlessly with other Azure services, making it an attractive option for businesses already using the Azure ecosystem.
The service offers flexible deployment options, allowing users to run TTS in the cloud, on-premises, or at the edge using containers. This versatility, combined with Azure's robust security features and compliance certifications, makes it particularly suitable for enterprise-level applications. Azure's Text-to-Speech also supports custom voice creation, enabling organizations to develop unique brand voices for consistent audio experiences across various touchpoints.
Key features of Microsoft Azure Text-to-Speech:
- Neural voices for highly natural speech output
- Flexible deployment options (cloud, on-premises, edge)
- Custom voice creation capabilities
- Integration with other Azure Cognitive Services
- Enterprise-grade security and compliance features
Play.ht offers a versatile TTS API that provides access to over 800 AI voices across 142 languages and accents. The platform is designed for scalability and real-time applications, with a low latency of under 300 milliseconds. Play.ht's API supports both REST and gRPC protocols, making it suitable for a wide range of projects and integration scenarios.
One of Play.ht's standout features is its ability to generate high-quality, natural-sounding voices with contextual awareness and emotional range. The platform also offers voice cloning capabilities, allowing users to create custom voices tailored to their specific needs. With its focus on high-fidelity output and streaming capabilities, Play.ht is well-suited for applications ranging from content creation to real-time conversational AI.
Key features of Play.ht:
- Over 800 lifelike AI voices across 142 languages and accents
- Low latency (under 300ms) for real-time applications
- Voice cloning and customization options
- Support for both REST and gRPC API protocols
- High-fidelity output suitable for streaming

Murf.ai provides a text-to-speech API that focuses on delivering high-quality, human-like voices for various applications. The platform offers over 120 voices across 20 languages, ensuring flexibility for diverse linguistic requirements. Murf.ai's API is designed to integrate seamlessly with existing technology stacks, making it a suitable choice for businesses looking to incorporate text-to-speech capabilities into their products or services.
While Murf.ai may not offer the lowest latency in the market, it compensates with its emphasis on voice quality and customization options. The API allows users to fine-tune various aspects of the generated speech, including pitch, speed, and emphasis. Murf.ai also provides features for team collaboration and role management, making it particularly useful for organizations working on content creation projects.
Key features of Murf.ai:
- Over 120 high-quality voices across 20 languages
- Extensive customization options for voice output
- Team collaboration and role management features
- Integration with multiple voice providers (e.g., Google, Amazon, IBM)
- Support for various audio output formats (MP3, WAV, FLAC)
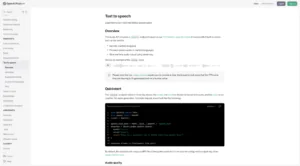
OpenAI's text-to-speech API leverages advanced deep learning models to generate natural and expressive speech from text inputs. While relatively new compared to some other offerings, OpenAI's API has quickly gained attention due to its high-quality output and the company's reputation for cutting-edge AI research. The API offers a selection of preset voices and supports two model variants optimized for different use cases.
One of the strengths of OpenAI's text-to-speech API is its ability to capture nuances in intonation and expression, resulting in highly natural-sounding speech. The API is designed to be easily integrated into various applications and supports streaming capabilities for real-time use cases. While it may not offer as many voices or languages as some competitors, OpenAI's focus on quality and ongoing improvements make it a compelling option for developers seeking state-of-the-art speech synthesis.
Key features of OpenAI's text-to-speech API:
- High-quality, natural-sounding speech synthesis
- Model variants optimized for different use cases
- Support for streaming audio output
- Easy integration with existing applications
- Ongoing improvements based on OpenAI's AI research

IBM Watson Text to Speech is a cloud-based API service that converts written text into natural-sounding audio across a variety of languages and voices. Leveraging advanced artificial intelligence and deep learning technologies, Watson TTS enables businesses and developers to enhance their applications, products, and services with high-quality voice interactions. The service is designed to improve customer experiences by allowing brands to communicate with users in their native languages, increase accessibility for individuals with different abilities, and automate customer service interactions to reduce wait times.
One of Watson TTS's strengths lies in its flexibility and customization options. Users can fine-tune various aspects of the generated speech, including pronunciation, volume, pitch, and speed, using SSML. The service also offers neural voices for more natural and expressive output, as well as the ability to create custom branded voices through its Premium tier. With its integration capabilities, particularly with Watson Assistant, IBM Watson Text to Speech provides a comprehensive solution for businesses looking to incorporate advanced voice technologies into their offerings.
Key features of IBM Watson Text to Speech:
- Neural voices for highly natural and expressive speech output
- Support for multiple languages and dialects
- Customizable speech parameters using SSML
- Integration with Watson Assistant for enhanced conversational AI
- Option to create custom branded voices (Premium feature)
The Bottom Line
As we've explored, the landscape of text-to-speech technology is rich with innovative solutions that cater to a wide array of needs and use cases. From Amazon Polly's seamless integration with AWS to ElevenLabs' advanced voice cloning capabilities, these APIs are pushing the boundaries of what's possible in speech synthesis. The ongoing advancements in neural networks and deep learning are continuously improving the naturalness and expressiveness of synthetic voices, making them increasingly indistinguishable from human speech.
Looking ahead, the future of text-to-speech APIs appears remarkably promising. As businesses and developers continue to harness these powerful tools, we can expect to see even more sophisticated applications emerge, ranging from personalized virtual assistants to immersive gaming experiences. The key to success in this rapidly evolving field lies in choosing the right API that aligns with your specific requirements, whether it's multilingual support, low latency, or customization options. By leveraging these cutting-edge text-to-speech solutions, organizations can enhance accessibility, improve user engagement, and unlock new possibilities in content creation and delivery.


#2024, #250, #Accessibility, #Ai, #AIResearch, #Amazon, #AmazonWebServices, #API, #APIs, #Applications, #Art, #Artificial, #ArtificialIntelligence, #Attention, #Audio, #Awareness, #AWS, #Azure, #BestOf, #Brands, #Business, #Capture, #Certifications, #Clone, #Cloud, #CloudServices, #Collaboration, #Compliance, #Comprehensive, #Containers, #Content, #ContentCreation, #Continuous, #ConversationalAi, #Creators, #CustomerExperience, #CustomerExperiences, #CustomerService, #Cutting, #DeepLearning, #Delay, #Deployment, #Developers, #Devices, #ELearning, #Easy, #Edge, #EdgeAI, #ElevenLabs, #Emphasis, #Enterprise, #Enterprises, #Executives, #Features, #Focus, #Future, #Game, #Gaming, #Giving, #Google, #GoogleCloud, #Healthcare, #Human, #IBM, #IbmWatson, #Industries, #Infrastructure, #Integration, #Intelligence, #IoT, #IoTDevices, #It, #Landscape, #Language, #Languages, #Latency, #Learning, #LESS, #List, #LowLatency, #MachineLearning, #Management, #Media, #Microsoft, #MicrosoftAzure, #Model, #Models, #Natural, #Network, #Networks, #Neural, #NeuralNetwork, #NeuralNetworks, #One, #Openai, #Organizations, #Other, #Platform, #Play, #Podcasts, #Positioning, #Pricing, #Productivity, #RealTime, #Research, #REST, #Security, #Space, #Speech, #Speed, #Streaming, #Success, #Synthesis, #TeamCollaboration, #Tech, #Technology, #Text, #TextToSpeech, #Time, #Tools, #Tts, #Tuning, #Video, #VirtualAssistants, #Voice, #VoiceCloning, #Voicebots, #Web, #Websites
Published on The Digital Insider at https://is.gd/g2n5J5.
Comments
Post a Comment
Comments are moderated.